
Openai2023发布会总结+GPT-4V API效果初步测试+GPT-4V模型结构揣测
一、发布会总结
凌晨看了openai发布会,很震撼,agent已经做的比市面上都完善了(无数AI startups哭晕)
放一些内容的链接:
b站中文字幕 https://www.bilibili.com/video/bv1ez4y1a7t2
youtube直播回放:https://www.youtube.com/watch?v=U9mJuUkhUzk
总结:https://openi.cn/110457.html
datawhale概览图: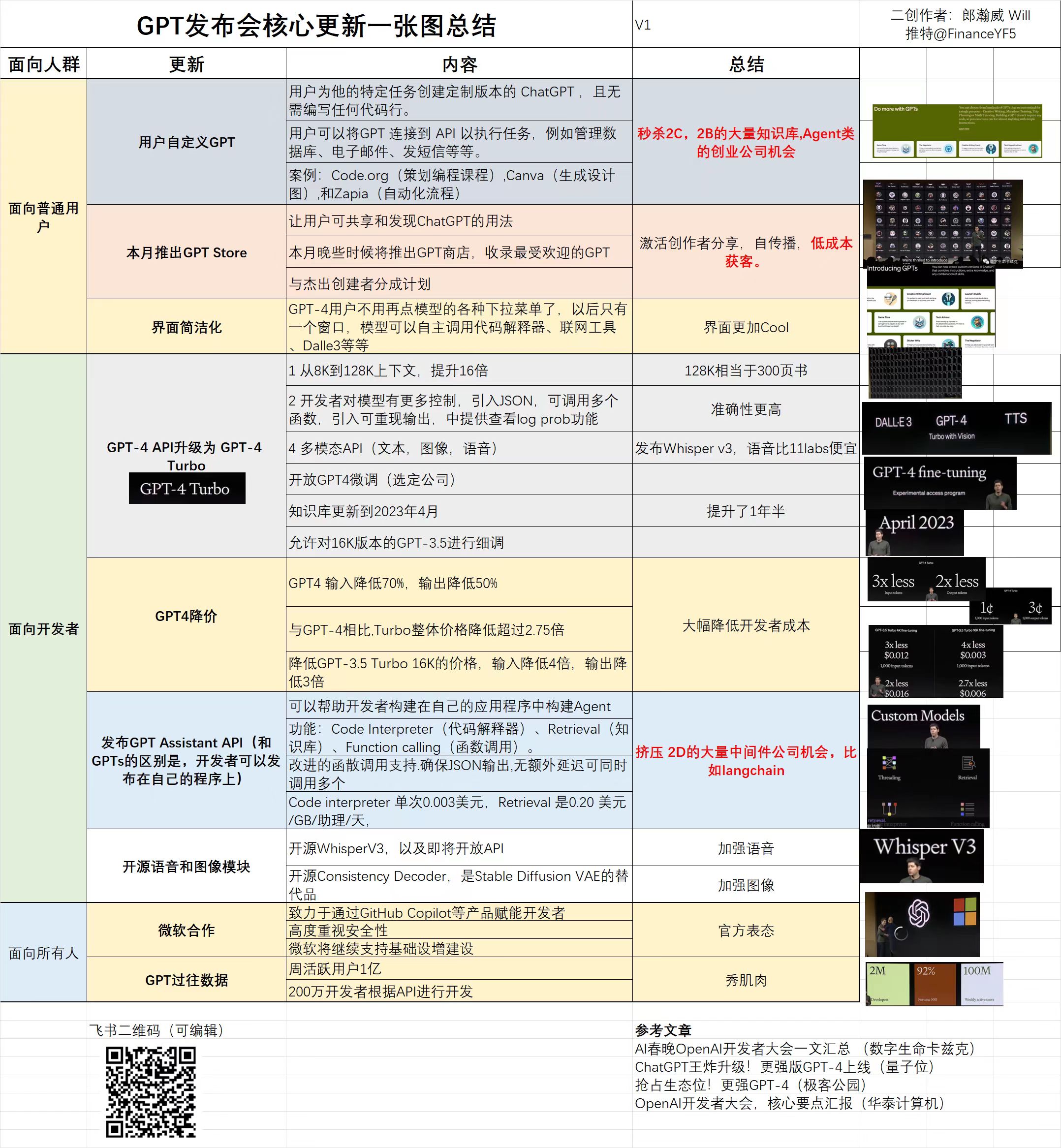
二、图文对话测试
因为之前一直关注图文对话模型,所以早上起来就快速测了一下新开放的GPT-4V API效果:
咱们先统一一下名字,根据openai官网:
GPT-4 with Vision, sometimes referred to as GPT-4V or gpt-4-vision-preview
所以下面我们就叫他GPT-4V API了
有请测试图片,学长拍摄的公司发的大闸蟹:

2.1 LlaVA大闸蟹测试
我们先看看LlaVA的效果,prompt就是问图里有什么(What's in this image):
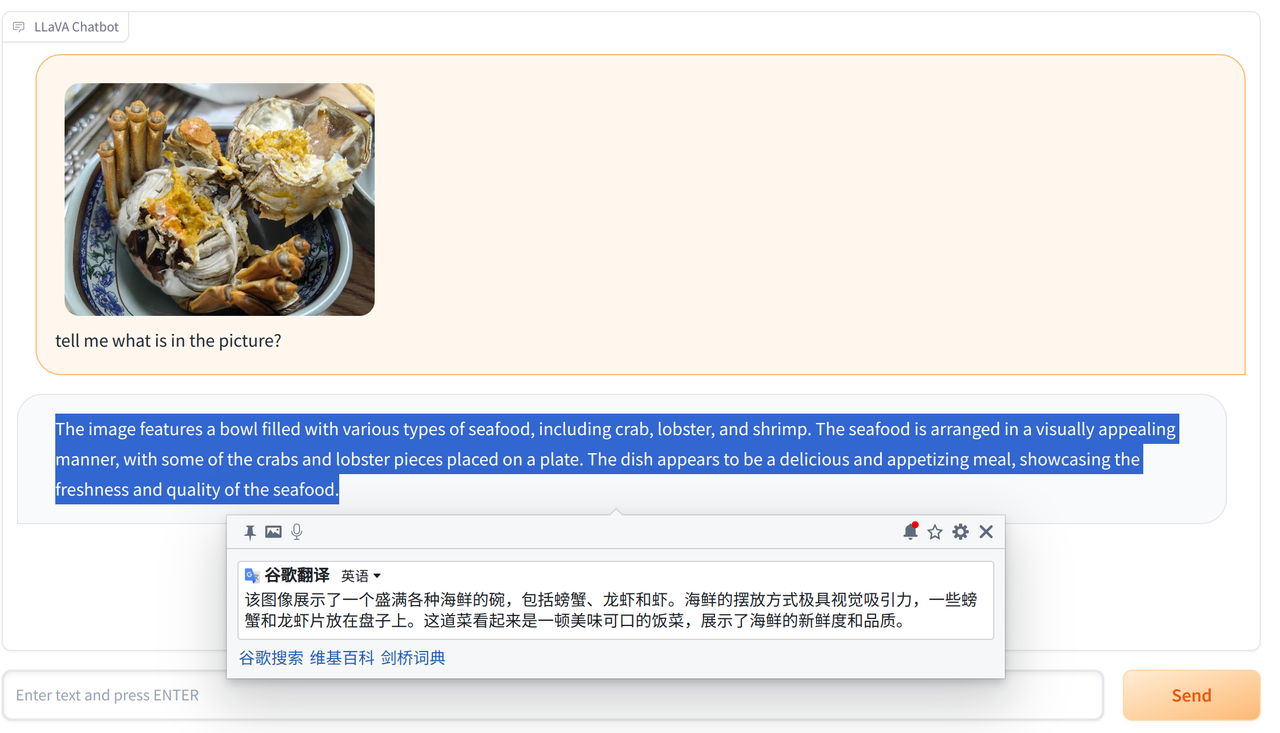 能识别出是海鲜的程度。。。
能识别出是海鲜的程度。。。
2.2 CogVLM大闸蟹测试
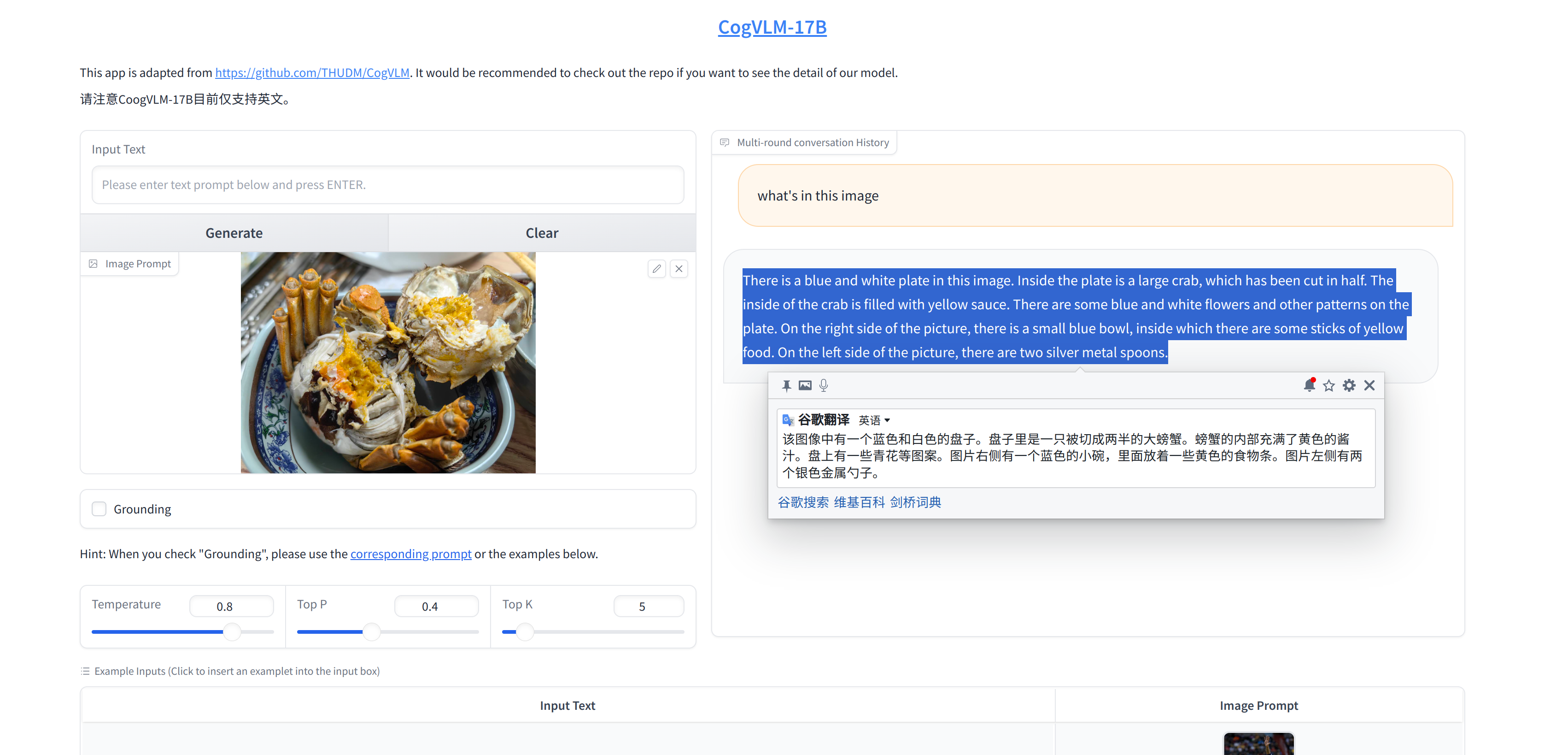 防止大家看不清,我把翻译好的中文复制下来:
防止大家看不清,我把翻译好的中文复制下来:
该图像中有一个蓝色和白色的盘子。盘子里是一只被切成两半的大螃蟹。螃蟹的内部充满了黄色的酱汁。盘上有一些青花等图案。图片右侧有一个蓝色的小碗,里面放着一些黄色的食物条。图片左侧有两个银色金属勺子。
可以说有点准头了,毕竟是17B模型,视觉部分参数量就比LlaVA多了
2.3 GPT-4V API大闸蟹测试
重量级来了
调用代码很简单,这是其中一种方式的大概写法,具体参考openai官网
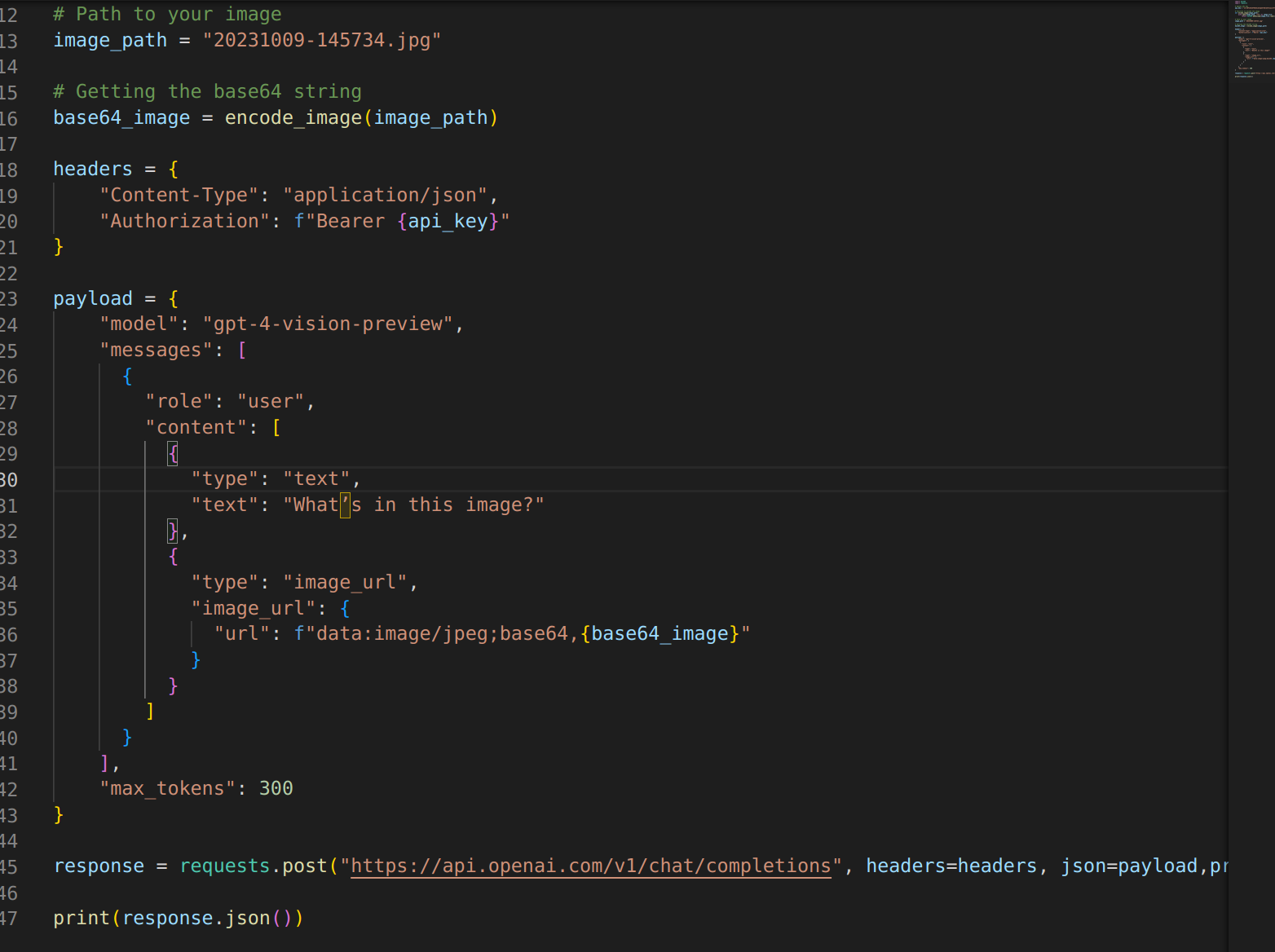 就是一个post请求,当然还要写个proxies的列表参数代理一下
就是一个post请求,当然还要写个proxies的列表参数代理一下
结果很炸裂:
This image shows a hairy crab, which is a delicacy in certain parts of the world, particularly in Shanghai and the Jiangsu province during the season when these crabs are harvested. Known for their furry claws and creamy roe, they are often steamed and served with vinegar, ginger, or other complementary condiments to enhance their rich flavor. The crab in the bowl appears to be opened up for consumption, revealing its inner contents, which includes creamy roe (the yellow substance), often considered a prized part of the dish. The bowl it's placed in features a traditional Chinese blue and white porcelain design.
翻译过来:
这张图片展示的是大闸蟹,这在世界某些地区是一种美味,尤其是在收获这些螃蟹的季节,在上海和江苏省。它们以毛茸茸的爪子和奶油般的鱼子而闻名,经常被蒸熟,配以醋、姜或其他补充调味品,以增强其浓郁的风味。碗里的螃蟹似乎是打开食用的,露出了里面的东西,其中包括奶油鱼子(黄色物质),通常被认为是这道菜的珍贵组成部分。它放置的碗采用了中国传统的青花瓷设计。
三、成本计算
GPT-4V API收费取决于图片的尺寸和参数detail(可选high和low),参考https://platform.openai.com/docs/guides/vision/calculating-costs
众所周知,openai有他自己的货币,token,根据模型类型和美元强绑定
这里模型是gpt-4-1106-vision-preview,input开销是0.01美刀每1k tokens,output是0.03美刀每1K tokens,和gpt-4-1106-preview的纯文本模型收费一致。
具体怎么收费的呢?openai给了几个示例:
1024 x 1024 square image in detail: high mode costs 765 tokens
花费765tokens,这是怎么计算来的呢?openai做了解释:
最大边1024小于2048,所以不做resize
最小边为1024,所以做scale down到768*768
最终需要4个512px的方块(512*512)来表示这个图像,花费 170*4 + 85 = 765
2048 x 4096 image in detail: high mode costs 1105 tokens
图片先缩放到1024 x 2048 以满足没有边大于2048
最小边是1024 所以进一步缩放到
768 x 1536需要6个512px方块, 最终花费 170 * 6 + 85 = 1105.
4096 x 8192 image in detail: low most costs 85 tokens
不管多大,low quality模型的图片都是固定价格,也就是 85tokens
总结一下high detail情况下的计算流程:
第一步,最大边不能超2048像素,不然就给你缩放到2048
第二步,将最小边缩放到768像素
算有几个方块,根据方块数来收费,再加上85的固定价格
四、模型结构揣测
文档中还有一些语句有助于推断模型结构:
For high rest mode, the short side of the image should be less than 768px and the long side should be less than 2,000px.
对于高分辨率模式,图像的短边应小于 768 像素,长边应小于 2,000 像素。
low will disable the “high res” model. The model will receive a low-res 512 x 512 version of the image, and represent the image with a budget of 65 tokens. This allows the API to return faster responses and consume fewer input tokens for use cases that do not require high detail.
low将禁用“高分辨率”模型。该模型将收到图像的低分辨率 512 x 512 版本,并以 65 个代币的预算表示该图像。这使得 API 能够返回更快的响应,并在不需要高细节的用例中消耗更少的输入令牌。
high will enable “high res” mode, which first allows the model to see the low res image and then creates detailed crops of input images as 512px squares based on the input image size. Each of the detailed crops uses twice the token budget (65 tokens) for a total of 129 tokens.
high 将启用“高分辨率”模式,该模式首先允许模型查看低分辨率图像,然后根据输入图像大小将输入图像创建为 512 像素正方形的详细裁剪。每个详细作物使用两倍的代币预算(65 个代币),总共 129 个代币。
这个收费标准似乎有点前后矛盾,不过收费方式可以参考。
首先是固定收费的85 tokens(或者是65 tokens),是因为一个表示整张图片的512px方块肯定会输入模型,不管你选哪个detail模式,这让模型有了整张图片的结构,而high detail进一步采取了分割图片为小块再输入模型的方式,让模型能看到图片的细节。
分割图片的思想其实一直都有,从Google 2020年提出ViT开始便有,最近开源的大模型架构也多采用ViT
比如LlaVA的架构(LlaVA仅支持一张图片输入):
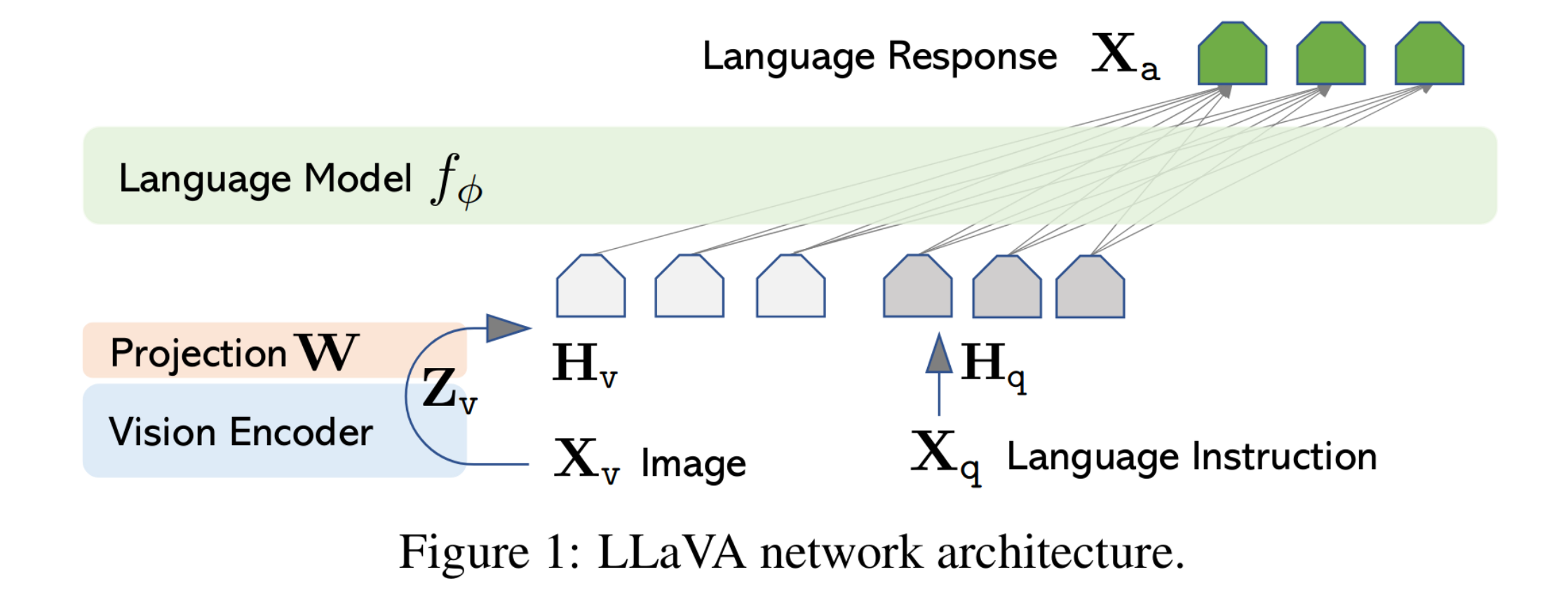
其中Vision Encoder就采用ViT-L/14(来自CLIP论文 2021年),不出意外的话GPT-4V也是类似架构,但拥有多图输入能力,这就要提到多图能力较强的DeepSpeed Visual-Chat(没错是微软的,所以和openai的模型类似很正常)
Visual-Chat架构(后面简称VC):
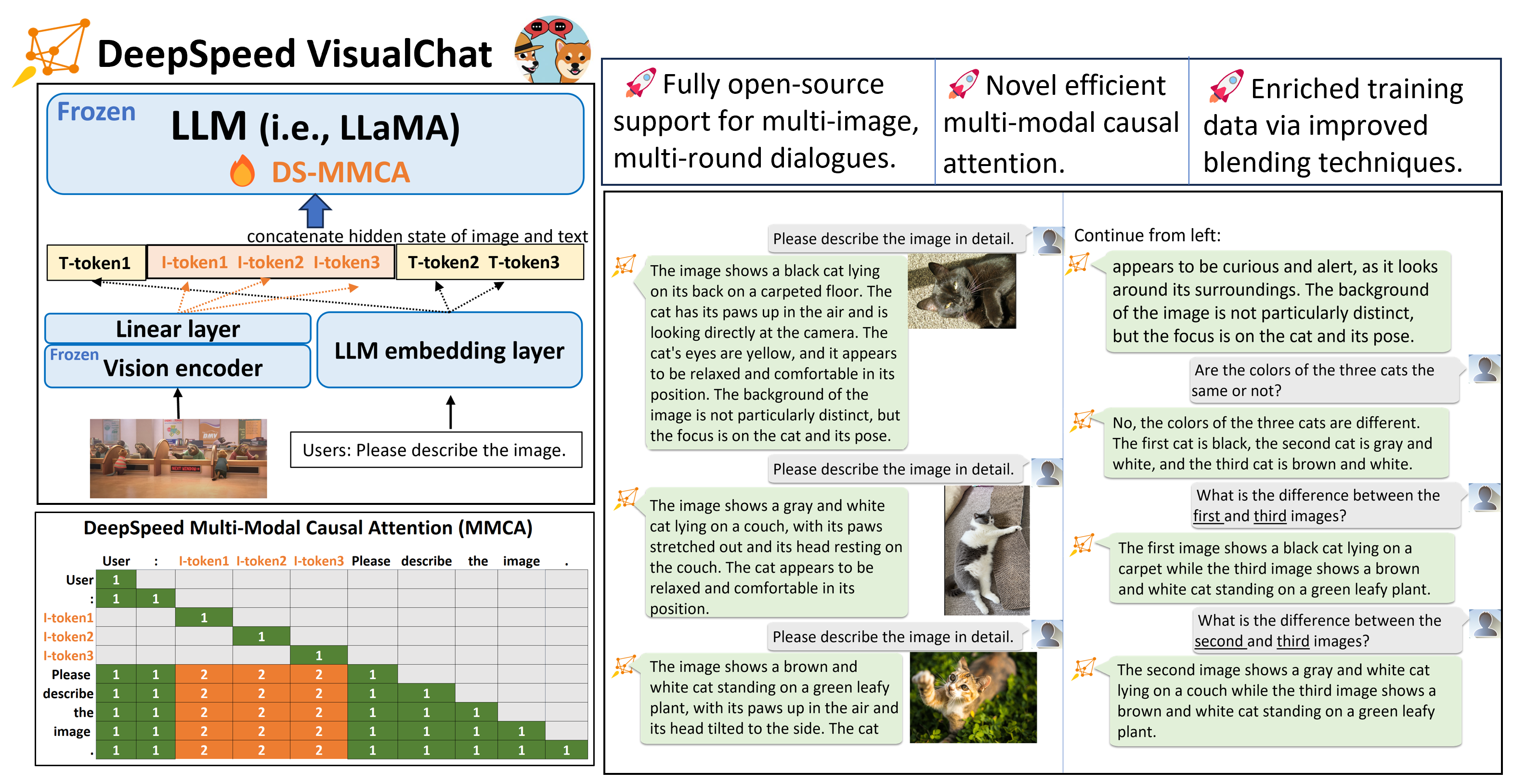 (但是因为截止目前没开源模型参数,只有训练代码和数据集,所以没法亲自测试)
(但是因为截止目前没开源模型参数,只有训练代码和数据集,所以没法亲自测试)
VC的突出特色就是支持多图对话,受限于上下文长度最多应该是8张,再通过改进的注意力机制MMCA,让文本token和图像token能产生奇妙的化学反应,达到更好的多图效果,这里的图片token是可以任意插入到文字token中的,我们不妨大胆猜测GPT-4V也是这种架构,那么模型decoder部分的输入可能就是这个样子(有理有据,令人信服):
| 文字tokens:"System:你是一个友好的视觉对话助手。。。,这里是一张图片的整体图:" | | 图片tokens:一个512px块代表整个图片 | | 文字tokens:"这是图片左上角的局部图"| | 图片tokens:一个512px块代表左上角 | | 文字tokens:"这是图片右上角的局部图"| | 图片tokens:一个512px块代表右上角 | | 文字tokens:"这是图片左下角的局部图"| | 图片tokens:一个512px块代表左下角 | | 文字tokens:"这是图片右上角的局部图"| | 图片tokens:一个512px块代表右下角 | | 文字tokens:""User:请问图片里有什么?","Robot:"|
这是笔者猜测的1024 x 1024图片的情况,具体decoder部分的实现openai肯定各种技巧拉满,那就不是笔者能猜测的了。
根据成本,一个512px块消耗85tokens(这肯定把一些辅助的文字tokens也计算进去了),然后一张图整体消耗最多差不多1000tokens,如果能实际测一下网页版GPT4-V的对话历史可能就能根据最大长度限制128k tokens大致验证一下了(实际对话还存了很多用户看不见的东西,只能模糊测试一下)。
2023.11.9 更新一下,有中科大大佬也在推测模型结构,大家可以在下面讨论:
https://www.zhihu.com/question/626046049/answer/3280968661?utm_psn=1705925704049434624
五、总结
gpt4-vision这个api是唯一能识别出来是大闸蟹的(其他只是说是螃蟹),这就其实对人类有一些帮助了,能看出他背后的训练集比开源的模型要大很多(openai是懂大数据集的),这次发布会也把模型的知识更新到2023年四月了,可以说是图文对话开始真正对人类有帮助了,他自己的介绍页面也说了,gpt4-vision没有弱化gpt4的能力,而是在gpt4上加了vision这个功能。还有一点,gpt4-vision的速度快的离谱,这个回答6-7秒就完整返回了,而正常在单卡A100上小模型不做优化,返回这段文字大概需要15到20秒。
原文链接:https://likegiver.com/archives/1699326331986,转载请注明原作者LikeGiver