
LLM微调入门项目分享
最近舍友在做LLM的微调,我正好有VLM相关微调的需求,所以也看看,记录一下几个项目
模型微调最官方的库肯定是huggingface的peft:https://github.com/huggingface/peft?tab=readme-ov-file,支持11种微调策略,下面的项目很多都基于peft
这里要强调一下概念:
PEFT(Parameter-Efficient Fine-Tuning)这个词本身代表一种策略,用于为各种应用巧妙地定制预训练语言模型 (PLM),而无需微调模型中的每个参数。大规模 PLM 在计算和存储方面可能过于昂贵。然而,PEFT 方法采取了一种更有针对性的方法,仅选择性地微调一小部分附加模型参数。这种有针对性的调整显着降低了所涉及的计算和存储成本。令人印象深刻的是,最近的尖端 PEFT 技术已经证明了与通过完全微调方法实现的性能水平相当,展示了它们在使 PLM 适应不同应用方面的效率和有效性。
而我们说的instruction tuning代表一种微调形式,还有许多其他形式:RLHF之类的:
指令调优代表微调的一种特殊形式,使用成对的输入输出指令来训练模型,使模型能够学习由这些指令指导的特定任务。
Consider the following input and output:
Input: “Provide a list of the most spoken languages”
Output: “English, French”
提供此输入和输出可以训练模型根据给定的指令理解和执行任务。这些指令涵盖了从撰写电子邮件到句子编辑的各种文本类型,从而增强了模型在各种指令驱动任务中的适应性。通过将模型暴露于不同的指令,它获得了强大的泛化能力,增强了生成与类人指令格式一致的准确响应的能力。
参考medium博客
还可以参考这个huggingface上的回答,下面让我们开始看项目:
1. 非常适合入门微调的一个代码库,白泽baize
https://github.com/project-baize/baize-chatbot
代码非常简单,特点是数据是chatgpt生存的,然后他在llama上微调,他提供了用chatgpt生成数据的脚本(有卡有钱就是牛)
2. DoctorGLM:https://github.com/xionghonglin/DoctorGLM?tab=readme-ov-file
基于chatglm-6b微调库:https://github.com/ssbuild/chatglm_finetuning
数据集:https://github.com/Toyhom/Chinese-medical-dialogue-data
该示例主要是用p-tuningv2方法,对比了lora方法。
这个库遇到了和我微调minigpt4时一样的问题,练着练着失去本来的能力了。
3. chatlaw,北大的法律大模型,基于姜子牙-13B,还有基于Anima-33B的版本,开源了demo版本
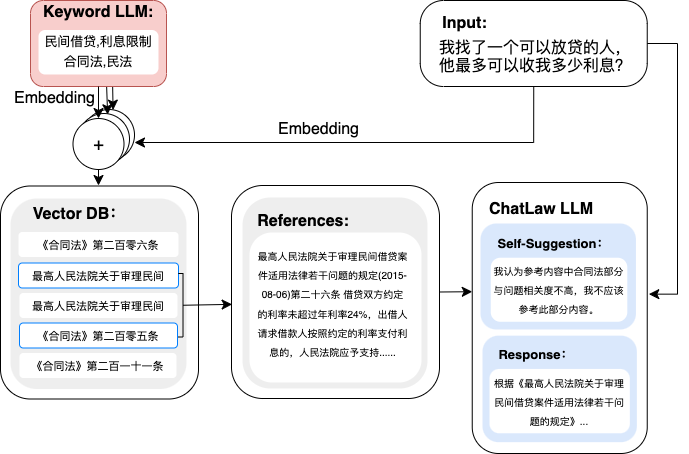
特点就是用了RAG和自我反思,然后训练了bert的embedding模型,缺点是所有训练细节一律没开源,数据只开源了一点点,网友推断是基于lora做的微调,demo在这:https://chatlaw.cloud/lawchat/#/
4. 本草(华佗),哈工大的一个项目:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
![]()
开源做的很好,特点他用于微调(微调策略应该是lora)的问答对是基于知识图谱用gpt3.5生成的,然后这个知识图谱又是用医学文献抽取的,这和一般的思路很不一样,我之前都是直接在原始数据上让gpt抽取的问答对的,他这样的好处可能是知识被更加显式得抽取出来了,他基于这个知识可以做到数据生成的多样性,一条知识可以生成很多不一样的问答对,这样可能有利于模型微调时掌握知识。
5. PMC-LLaMA 上交的,不是很知名,但是开源得不错:https://github.com/chaoyi-wu/PMC-LLaMA?tab=readme-ov-file
特点是分两步微调,第一步他叫pretrain,目的是让模型获取医学方面知识,第二部instruction tuning是让模型能够医生口吻对话(我推测的)
我粗略看了看,印象就是他这套微调方式很全,很系统,基于llama13B和7B。

缺点是他用S2ORC数据集来做了第一步微调,这个数据集似乎要申请。