
基于LLM的问答对提取
2024-04-11更新:新增自动朗读音乐
(自动朗读 --- suno-ai)
背景
现在LLM训练需要数据,而数据清洗又可以基于LLM(有环图的依赖关系)
因为业务需要,最近在用gpt-3.5基于网络数据生成、筛选、润色出很多问答对,效果似乎还挺不错(结合场景需要,我让他模仿客服语气的)
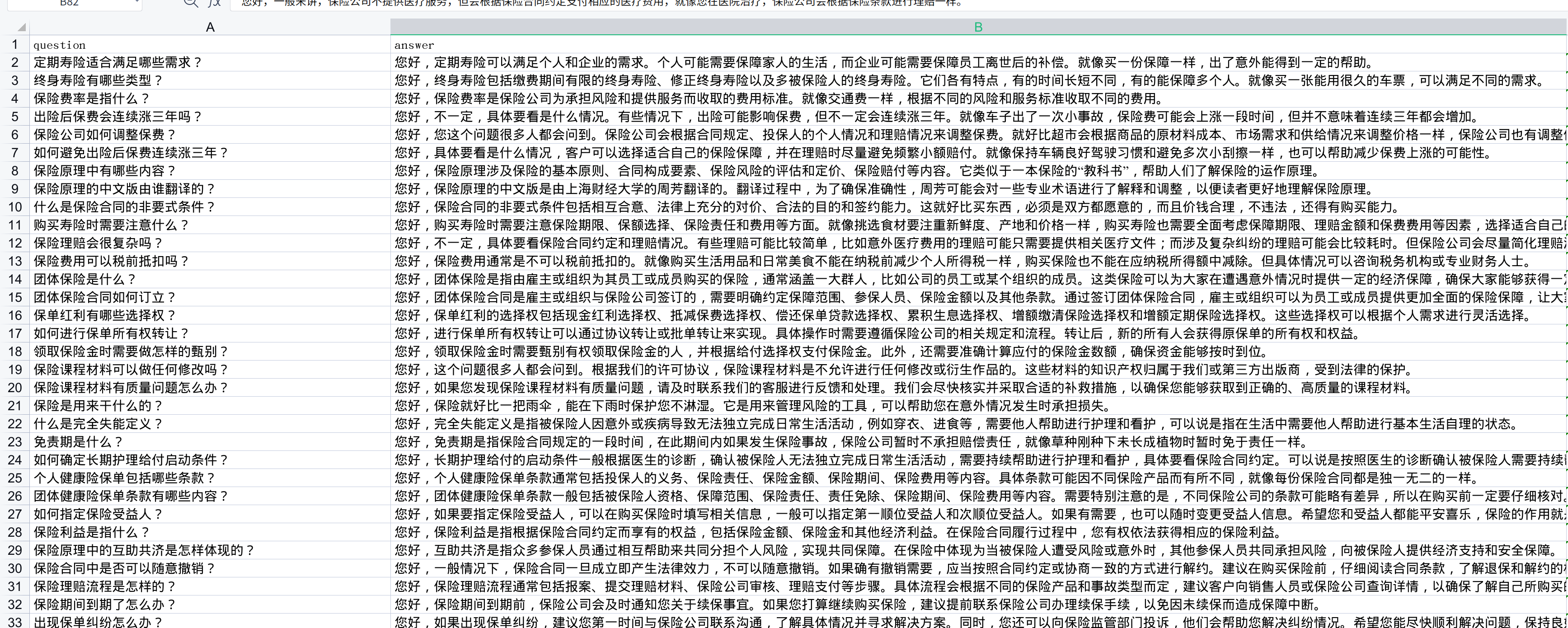 但是目前我没有参考很多资料,这基本是我拍脑袋做的:数据加载进来(用了llama-index之类的)——>让gpt生成json格式问答对——>让gpt筛选——>让gpt润色(业务需要无法开源,但是这思路很简单,大家自己实现应该也不难,这篇文章主要是讲讲涉及到的技术)
但是目前我没有参考很多资料,这基本是我拍脑袋做的:数据加载进来(用了llama-index之类的)——>让gpt生成json格式问答对——>让gpt筛选——>让gpt润色(业务需要无法开源,但是这思路很简单,大家自己实现应该也不难,这篇文章主要是讲讲涉及到的技术)
我觉得这个过程非常不专业,因此我开始搜索一点网上做法参考参考
目前看到一篇6个月前的:https://towardsdatascience.com/from-chaos-to-clarity-streamlining-data-cleansing-using-large-language-models-a539fa0b2d90 他的应用场景是一个序列分类场景,在我这场景也多少用的到
人家确实很专业,我认为他的代码很优雅,prompt也更清晰,所以先放在这参考,等我把他参考文献先看一遍。
涉及技术:
1. prompt工程(上限低但成本也很低的快速提高大模型效果的好办法)
我之前对prompt工程理解很浅而且不是很感兴趣,之前也做过连续prompt的fine-tune,但是在我那个场景下fine-tune prompt效果不佳,之前大模型刚出来很多人能靠prompt工程水文章,但是这东西和应用场景非常贴近,还和模型具体咋练的有关,越来越难水了,最近似乎在流行用大模型生成prompt。
现在由于业务需求(我是负责人的乙方!),所以我还是要秉持专业精神学习一下prompt工程!
教程1: OpenAI的官方短文:Best practices for prompt engineering with OpenAI API (十分钟)
https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
八条简单小技巧,教你当个做个人的甲方,第二条“Put instructions at the beginning of the prompt and use ### or """ to separate the instruction and context”感觉对我很有用,第八条有点骚操作了,多加个import效果就更好?很难绷
数据提取时,temperature应该设置为0?我之前好像忽略了。。。
教程2: OpenAI的官方大教程:Guides: Prompt engineering
https://platform.openai.com/docs/guides/prompt-engineering
这个教程不仅更加专业,而且对prompt的理解很有趣,把chain of thought和rag都算进prompt工程了(所以我一直在干prompt工程,只缘身在此山中了)
有个点蛮重要的,就是应该创建evaluation来test prompt的改变,然后他推荐了自己的项目:https://github.com/openai/evals
但是好像私货很多,似乎不是很适合用来测试自己的模型,只支持openai的
2. llama-index
3. streamlit (可选,我用来可视化的)
官方参考文档https://docs.streamlit.io/library/advanced-features/session-state#initialization
当前效果:
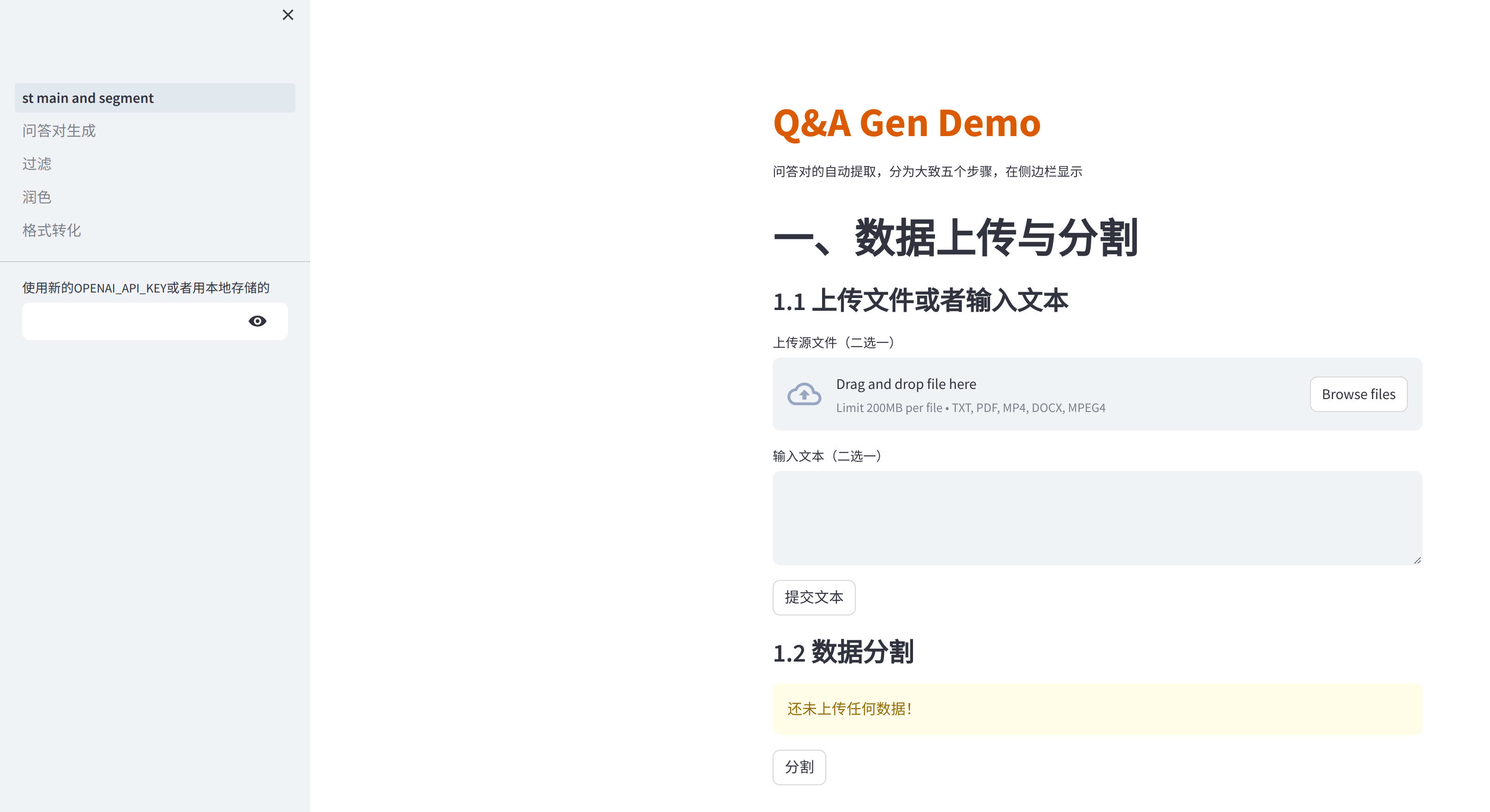 目前已经支持多种文件格式的问答对提取(pdf、txt、docx、mp4),过滤、润色、格式转化还未集成进来,其实即使集成进来对效果的提升也有限,我认为还是得在问答对生成这步骤对pipeline做一些修改,现在基于单个chunk提取问答对,因为上下文信息的缺失,提取出来的信息并不能达到与上下文独立出来,许多问答对无法单独拿出来作为一个知识片段。如果在润色步骤引入不同的上下文,应该可以弥补这个问题。
目前已经支持多种文件格式的问答对提取(pdf、txt、docx、mp4),过滤、润色、格式转化还未集成进来,其实即使集成进来对效果的提升也有限,我认为还是得在问答对生成这步骤对pipeline做一些修改,现在基于单个chunk提取问答对,因为上下文信息的缺失,提取出来的信息并不能达到与上下文独立出来,许多问答对无法单独拿出来作为一个知识片段。如果在润色步骤引入不同的上下文,应该可以弥补这个问题。
问题示例
问答对独立性问题:比如我拿我们的课本《大数据技术原理与应用(第三版) (林子雨)》做一个提取,即使我在system_prompt中要求提取独立于上下文的问答对,但是提取出来的question还是会用“这本书”这样的字眼,chunk中是包括了书名的,但是模型没有充分理解我们的需求。

这个问题也可能由于该chunk中就是没有包括书名导致,比如下图中各类命令的question,其实都缺乏了语境是要在linux系统中:
